复合类型
顾名思义,复合类型是由其它类型组合而成的,最典型的就是结构体 struct 和枚举 enum。例如平面上的一个点 point(x, y),它由两个数值类型的值 x 和 y 组合而来。我们无法单独去维护这两个数值,因为单独一个 x 或者 y 是含义不完整的,无法标识平面上的一个点,应该把它们看作一个整体去理解和处理。
来看一段代码,它使用我们之前学过的内容来构建文件操作:
#![allow(unused_variables)]
type File = String;
fn open(f: &mut File) -> bool {
true
}
fn close(f: &mut File) -> bool {
true
}
#[allow(dead_code)]
fn read(f: &mut File, save_to: &mut Vec<u8>) -> ! {
unimplemented!()
}
fn main() {
let mut f1 = File::from("f1.txt");
open(&mut f1);
//read(&mut f1, &mut vec![]);
close(&mut f1);
}接下来的学习非常类似原型设计:有的方法只提供 API 接口,但是不提供具体实现。此外,有的变量在声明之后并未使用,因此在这个阶段需要排除一些编译器噪音(Rust 在编译的时候会扫描代码,变量声明后未使用会以 warning 警告的形式进行提示),引入 #![allow(unused_variables)] 属性标记,该标记会告诉编译器忽略未使用的变量,不要抛出 warning 警告,具体的常见编译器属性你可以在这里查阅:编译器属性标记。
read 函数也非常有趣,它返回一个 ! 类型,这个表明该函数是一个发散函数,不会返回任何值,包括 ()。unimplemented!() 告诉编译器该函数尚未实现,unimplemented!() 标记通常意味着我们期望快速完成主要代码,回头再通过搜索这些标记来完成次要代码,类似的标记还有 todo!(),当代码执行到这种未实现的地方时,程序会直接报错。你可以反注释 read(&mut f1, &mut vec![]); 这行,然后再观察下结果。
同时,从代码设计角度来看,关于文件操作的类型和函数应该组织在一起,散落得到处都是,是难以管理和使用的。而且通过 open(&mut f1) 进行调用,也远没有使用 f1.open() 来调用好,这就体现出了只使用基本类型的局限性:无法从更高的抽象层次去简化代码。
接下来,我们将引入一个高级数据结构 —— 结构体 struct,来看看复合类型是怎样更好的解决这类问题。 开始之前,先来看看 Rust 的重点也是难点:字符串 String 和 &str。
字符串
首先来看段很简单的代码:
fn main() {
let my_name = "Pascal";
greet(my_name);
}
fn greet(name: String) {
println!("Hello, {}!", name);
}greet 函数接受一个字符串类型的 name 参数,然后打印到终端控制台中,非常好理解,你们猜猜,这段代码能否通过编译?
error[E0308]: mismatched types
--> src/main.rs:3:11
|
3 | greet(my_name);
| ^^^^^^^
| |
| expected struct `std::string::String`, found `&str`
| help: try using a conversion method: `my_name.to_string()`
error: aborting due to previous error
Bingo,果然报错了,编译器提示 greet 函数需要一个 String 类型的字符串,却传入了一个 &str 类型的字符串,相信读者心中现在一定有几头草泥马呼啸而过,怎么字符串也能整出这么多花活?
在讲解字符串之前,先来看看什么是切片?
切片(slice)
切片并不是 Rust 独有的概念,在 Go 语言中就非常流行,它允许你引用集合中部分连续的元素序列,而不是引用整个集合。
对于字符串而言,切片就是对 String 类型中某一部分的引用,它看起来像这样:
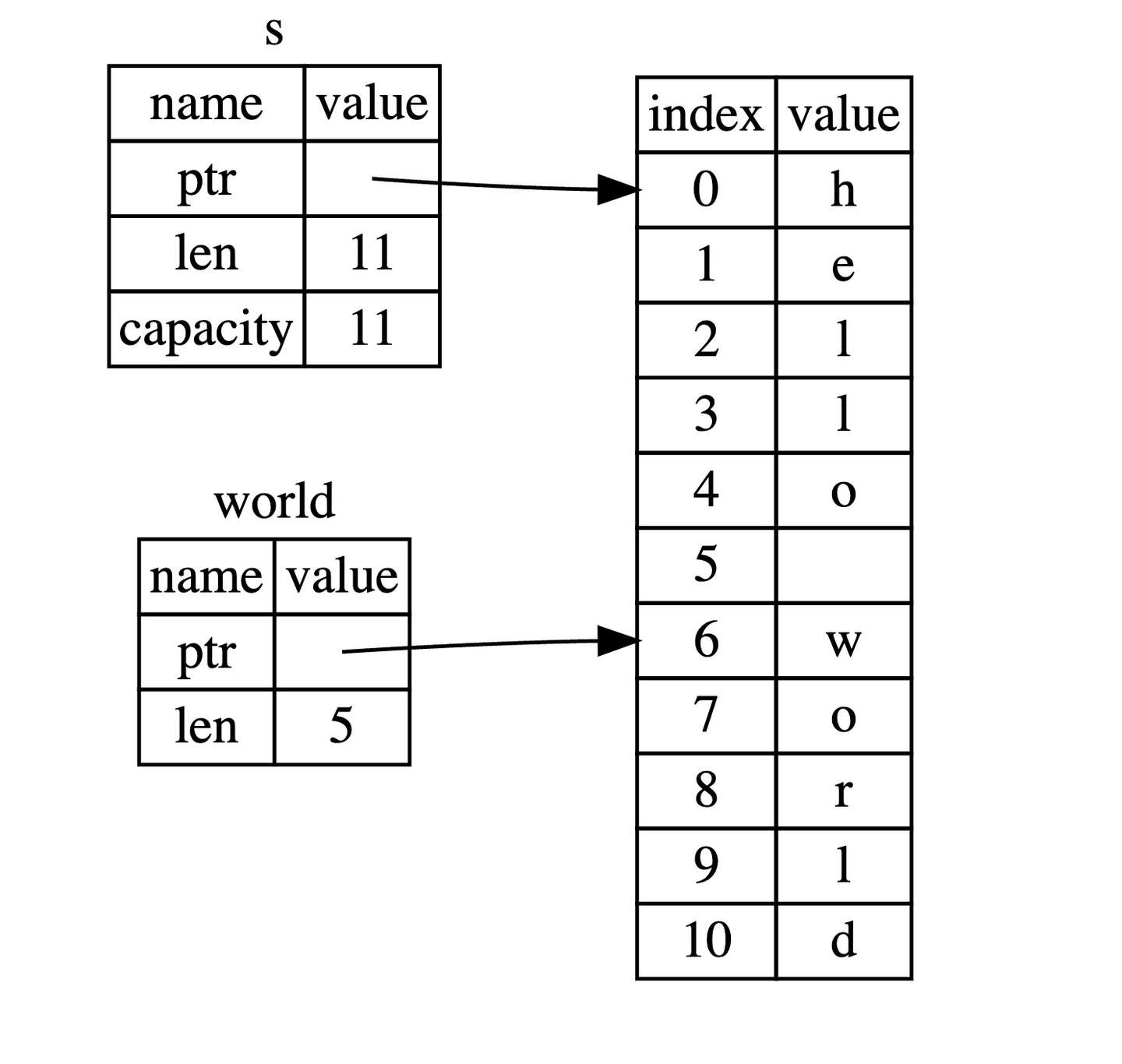
let s = String::from("hello world");
let hello = &s[0..5];
let world = &s[6..11];
hello 没有引用整个 String s,而是引用了 s 的一部分内容,通过 [0..5] 的方式来指定。
这就是创建切片的语法,使用方括号包括的一个序列:[开始索引..终止索引],其中开始索引是切片中第一个元素的索引位置,而终止索引是最后一个元素后面的索引位置。换句话说,这是一个 右半开区间(或称为左闭右开区间)——指的是在区间的左端点是包含在内的,而右端点是不包含在内的。在切片数据结构内部会保存开始的位置和切片的长度,其中长度是通过 终止索引 - 开始索引 的方式计算得来的。
对于 let world = &s[6..11]; 来说,world 是一个切片,该切片的指针指向 s 的第 7 个字节(索引从 0 开始, 6 是第 7 个字节),且该切片的长度是 5 个字节。
在使用 Rust 的 .. range 序列语法时,如果你想从索引 0 开始,可以使用如下的方式,这两个是等效的:
let s = String::from("hello");
let slice = &s[0..2];
let slice = &s[..2];
同样的,如果你的切片想要包含 String 的最后一个字节,则可以这样使用:
let s = String::from("hello");
let len = s.len();
let slice = &s[4..len];
let slice = &s[4..];
你也可以截取完整的 String 切片:
let s = String::from("hello");
let len = s.len();
let slice = &s[0..len];
let slice = &s[..];
在对字符串使用切片语法时需要格外小心,切片的索引必须落在字符之间的边界位置,也就是 UTF-8 字符的边界,例如中文在 UTF-8 中占用三个字节,下面的代码就会崩溃:
let s = "中国人"; let a = &s[0..2]; println!("{}",a);因为我们只取
s字符串的前两个字节,但是本例中每个汉字占用三个字节,因此没有落在边界处,也就是连中字都取不完整,此时程序会直接崩溃退出,如果改成&s[0..3],则可以正常通过编译。 因此,当你需要对字符串做切片索引操作时,需要格外小心这一点,关于该如何操作 UTF-8 字符串,参见这里。
字符串切片的类型标识是 &str,因此我们可以这样声明一个函数,输入 String 类型,返回它的切片:fn first_word(s: &String) -> &str 。
有了切片就可以写出这样的代码:
fn main() {
let mut s = String::from("hello world");
let word = first_word(&s);
s.clear(); // error!
println!("the first word is: {}", word);
}
fn first_word(s: &String) -> &str {
&s[..1]
}编译器报错如下:
error[E0502]: cannot borrow `s` as mutable because it is also borrowed as immutable
--> src/main.rs:18:5
|
16 | let word = first_word(&s);
| -- immutable borrow occurs here
17 |
18 | s.clear(); // error!
| ^^^^^^^^^ mutable borrow occurs here
19 |
20 | println!("the first word is: {}", word);
| ---- immutable borrow later used here
回忆一下借用的规则:当我们已经有了可变借用时,就无法再拥有不可变的借用。因为 clear 需要清空改变 String,因此它需要一个可变借用(利用 VSCode 可以看到该方法的声明是 pub fn clear(&mut self) ,参数是对自身的可变借用 );而之后的 println! 又使用了不可变借用,也就是在 s.clear() 处可变借用与不可变借用试图同时生效,因此编译无法通过。
从上述代码可以看出,Rust 不仅让我们的 API 更加容易使用,而且也在编译期就消除了大量错误!
其它切片
因为切片是对集合的部分引用,因此不仅仅字符串有切片,其它集合类型也有,例如数组:
let a = [1, 2, 3, 4, 5];
let slice = &a[1..3];
assert_eq!(slice, &[2, 3]);
该数组切片的类型是 &[i32],数组切片和字符串切片的工作方式是一样的,例如持有一个引用指向原始数组的某个元素和长度。
字符串字面量是切片
之前提到过字符串字面量,但是没有提到它的类型:
let s = "Hello, world!";
实际上,s 的类型是 &str,因此你也可以这样声明:
let s: &str = "Hello, world!";
该切片指向了程序可执行文件中的某个点,这也是为什么字符串字面量是不可变的,因为 &str 是一个不可变引用。
了解完切片,可以进入本节的正题了。
什么是字符串?
顾名思义,字符串是由字符组成的连续集合,但是在上一节中我们提到过,Rust 中的字符是 Unicode 类型,因此每个字符占据 4 个字节内存空间,但是在字符串中不一样,字符串是 UTF-8 编码,也就是字符串中的字符所占的字节数是变化的(1 - 4),这样有助于大幅降低字符串所占用的内存空间。
Rust 在语言级别,只有一种字符串类型: str,它通常是以引用类型出现 &str,也就是上文提到的字符串切片。虽然语言级别只有上述的 str 类型,但是在标准库里,还有多种不同用途的字符串类型,其中使用最广的即是 String 类型。
str 类型是硬编码进可执行文件,也无法被修改,但是 String 则是一个可增长、可改变且具有所有权的 UTF-8 编码字符串,当 Rust 用户提到字符串时,往往指的就是 String 类型和 &str 字符串切片类型,这两个类型都是 UTF-8 编码。
除了 String 类型的字符串,Rust 的标准库还提供了其他类型的字符串,例如 OsString, OsStr, CString 和 CStr 等,注意到这些名字都以 String 或者 Str 结尾了吗?它们分别对应的是具有所有权和被借用的变量。
String 与 &str 的转换
在之前的代码中,已经见到好几种从 &str 类型生成 String 类型的操作:
String::from("hello,world")"hello,world".to_string()
那么如何将 String 类型转为 &str 类型呢?答案很简单,取引用即可:
fn main() {
let s = String::from("hello,world!");
say_hello(&s);
say_hello(&s[..]);
say_hello(s.as_str());
}
fn say_hello(s: &str) {
println!("{}",s);
}实际上这种灵活用法是因为 deref 隐式强制转换,具体我们会在 Deref 特征进行详细讲解。
字符串索引
在其它语言中,使用索引的方式访问字符串的某个字符或者子串是很正常的行为,但是在 Rust 中就会报错:
let s1 = String::from("hello");
let h = s1[0];
该代码会产生如下错误:
3 | let h = s1[0];
| ^^^^^ `String` cannot be indexed by `{integer}`
|
= help: the trait `Index<{integer}>` is not implemented for `String`
深入字符串内部
字符串的底层的数据存储格式实际上是[ u8 ],一个字节数组。对于 let hello = String::from("Hola"); 这行代码来说,Hola 的长度是 4 个字节,因为 "Hola" 中的每个字母在 UTF-8 编码中仅占用 1 个字节,但是对于下面的代码呢?
let hello = String::from("中国人");
如果问你该字符串多长,你可能会说 3,但是实际上是 9 个字节的长度,因为大部分常用汉字在 UTF-8 中的长度是 3 个字节,因此这种情况下对 hello 进行索引,访问 &hello[0] 没有任何意义,因为你取不到 中 这个字符,而是取到了这个字符三个字节中的第一个字节,这是一个非常奇怪而且难以理解的返回值。
字符串的不同表现形式
现在看一下用梵文写的字符串 “नमस्ते”, 它底层的字节数组如下形式:
[224, 164, 168, 224, 164, 174, 224, 164, 184, 224, 165, 141, 224, 164, 164,
224, 165, 135]
长度是 18 个字节,这也是计算机最终存储该字符串的形式。如果从字符的形式去看,则是:
['न', 'म', 'स', '्', 'त', 'े']
但是这种形式下,第四和六两个字母根本就不存在,没有任何意义,接着再从字母串的形式去看:
["न", "म", "स्", "ते"]
所以,可以看出来 Rust 提供了不同的字符串展现方式,这样程序可以挑选自己想要的方式去使用,而无需去管字符串从人类语言角度看长什么样。
还有一个原因导致了 Rust 不允许去索引字符串:因为索引操作,我们总是期望它的性能表现是 O(1),然而对于 String 类型来说,无法保证这一点,因为 Rust 可能需要从 0 开始去遍历字符串来定位合法的字符。
字符串切片
前文提到过,字符串切片是非常危险的操作,因为切片的索引是通过字节来进行,但是字符串又是 UTF-8 编码,因此你无法保证索引的字节刚好落在字符的边界上,例如:
let hello = "中国人";
let s = &hello[0..2];
运行上面的程序,会直接造成崩溃:
thread 'main' panicked at 'byte index 2 is not a char boundary; it is inside '中' (bytes 0..3) of `中国人`', src/main.rs:4:14
note: run with `RUST_BACKTRACE=1` environment variable to display a backtrace
这里提示的很清楚,我们索引的字节落在了 中 字符的内部,这种返回没有任何意义。
因此在通过索引区间来访问字符串时,需要格外的小心,一不注意,就会导致你程序的崩溃!
操作字符串
由于 String 是可变字符串,下面介绍 Rust 字符串的修改,添加,删除等常用方法:
追加 (Push)
在字符串尾部可以使用 push() 方法追加字符 char,也可以使用 push_str() 方法追加字符串字面量。这两个方法都是在原有的字符串上追加,并不会返回新的字符串。由于字符串追加操作要修改原来的字符串,则该字符串必须是可变的,即字符串变量必须由 mut 关键字修饰。
示例代码如下:
fn main() {
let mut s = String::from("Hello ");
s.push_str("rust");
println!("追加字符串 push_str() -> {}", s);
s.push('!');
println!("追加字符 push() -> {}", s);
}代码运行结果:
追加字符串 push_str() -> Hello rust
追加字符 push() -> Hello rust!
插入 (Insert)
可以使用 insert() 方法插入单个字符 char,也可以使用 insert_str() 方法插入字符串字面量,与 push() 方法不同,这俩方法需要传入两个参数,第一个参数是字符(串)插入位置的索引,第二个参数是要插入的字符(串),索引从 0 开始计数,如果越界则会发生错误。由于字符串插入操作要修改原来的字符串,则该字符串必须是可变的,即字符串变量必须由 mut 关键字修饰。
示例代码如下:
fn main() {
let mut s = String::from("Hello rust!");
s.insert(5, ',');
println!("插入字符 insert() -> {}", s);
s.insert_str(6, " I like");
println!("插入字符串 insert_str() -> {}", s);
}代码运行结果:
插入字符 insert() -> Hello, rust!
插入字符串 insert_str() -> Hello, I like rust!
替换 (Replace)
如果想要把字符串中的某个字符串替换成其它的字符串,那可以使用 replace() 方法。与替换有关的方法有三个。
1、replace
该方法可适用于 String 和 &str 类型。replace() 方法接收两个参数,第一个参数是要被替换的字符串,第二个参数是新的字符串。该方法会替换所有匹配到的字符串。该方法是返回一个新的字符串,而不是操作原来的字符串。
示例代码如下:
fn main() {
let string_replace = String::from("I like rust. Learning rust is my favorite!");
let new_string_replace = string_replace.replace("rust", "RUST");
dbg!(new_string_replace);
}代码运行结果:
new_string_replace = "I like RUST. Learning RUST is my favorite!"
2、replacen
该方法可适用于 String 和 &str 类型。replacen() 方法接收三个参数,前两个参数与 replace() 方法一样,第三个参数则表示替换的个数。该方法是返回一个新的字符串,而不是操作原来的字符串。
示例代码如下:
fn main() {
let string_replace = "I like rust. Learning rust is my favorite!";
let new_string_replacen = string_replace.replacen("rust", "RUST", 1);
dbg!(new_string_replacen);
}代码运行结果:
new_string_replacen = "I like RUST. Learning rust is my favorite!"
3、replace_range
该方法仅适用于 String 类型。replace_range 接收两个参数,第一个参数是要替换字符串的范围(Range),第二个参数是新的字符串。该方法是直接操作原来的字符串,不会返回新的字符串。该方法需要使用 mut 关键字修饰。
示例代码如下:
fn main() {
let mut string_replace_range = String::from("I like rust!");
string_replace_range.replace_range(7..8, "R");
dbg!(string_replace_range);
}代码运行结果:
string_replace_range = "I like Rust!"
删除 (Delete)
与字符串删除相关的方法有 4 个,它们分别是 pop(),remove(),truncate(),clear()。这四个方法仅适用于 String 类型。
1、 pop —— 删除并返回字符串的最后一个字符
该方法是直接操作原来的字符串。但是存在返回值,其返回值是一个 Option 类型,如果字符串为空,则返回 None。
示例代码如下:
fn main() {
let mut string_pop = String::from("rust pop 中文!");
let p1 = string_pop.pop();
let p2 = string_pop.pop();
dbg!(p1);
dbg!(p2);
dbg!(string_pop);
}代码运行结果:
p1 = Some(
'!',
)
p2 = Some(
'文',
)
string_pop = "rust pop 中"
2、 remove —— 删除并返回字符串中指定位置的字符
该方法是直接操作原来的字符串。但是存在返回值,其返回值是删除位置的字符串,只接收一个参数,表示该字符起始索引位置。remove() 方法是按照字节来处理字符串的,如果参数所给的位置不是合法的字符边界,则会发生错误。
示例代码如下:
fn main() {
let mut string_remove = String::from("测试remove方法");
println!(
"string_remove 占 {} 个字节",
std::mem::size_of_val(string_remove.as_str())
);
// 删除第一个汉字
string_remove.remove(0);
// 下面代码会发生错误
// string_remove.remove(1);
// 直接删除第二个汉字
// string_remove.remove(3);
dbg!(string_remove);
}代码运行结果:
string_remove 占 18 个字节
string_remove = "试remove方法"
3、truncate —— 删除字符串中从指定位置开始到结尾的全部字符
该方法是直接操作原来的字符串。无返回值。该方法 truncate() 方法是按照字节来处理字符串的,如果参数所给的位置不是合法的字符边界,则会发生错误。
示例代码如下:
fn main() {
let mut string_truncate = String::from("测试truncate");
string_truncate.truncate(3);
dbg!(string_truncate);
}代码运行结果:
string_truncate = "测"
4、clear —— 清空字符串
该方法是直接操作原来的字符串。调用后,删除字符串中的所有字符,相当于 truncate() 方法参数为 0 的时候。
示例代码如下:
fn main() {
let mut string_clear = String::from("string clear");
string_clear.clear();
dbg!(string_clear);
}代码运行结果:
string_clear = ""
连接 (Concatenate)
1、使用 + 或者 += 连接字符串
使用 + 或者 += 连接字符串,要求右边的参数必须为字符串的切片引用(Slice)类型。其实当调用 + 的操作符时,相当于调用了 std::string 标准库中的 add() 方法,这里 add() 方法的第二个参数是一个引用的类型。因此我们在使用 + 时, 必须传递切片引用类型。不能直接传递 String 类型。+ 是返回一个新的字符串,所以变量声明可以不需要 mut 关键字修饰。
示例代码如下:
fn main() {
let string_append = String::from("hello ");
let string_rust = String::from("rust");
// &string_rust会自动解引用为&str
let result = string_append + &string_rust;
let mut result = result + "!"; // `result + "!"` 中的 `result` 是不可变的
result += "!!!";
println!("连接字符串 + -> {}", result);
}代码运行结果:
连接字符串 + -> hello rust!!!!
add() 方法的定义:
fn add(self, s: &str) -> String
因为该方法涉及到更复杂的特征功能,因此我们这里简单说明下:
fn main() {
let s1 = String::from("hello,");
let s2 = String::from("world!");
// 在下句中,s1的所有权被转移走了,因此后面不能再使用s1
let s3 = s1 + &s2;
assert_eq!(s3,"hello,world!");
// 下面的语句如果去掉注释,就会报错
// println!("{}",s1);
}self 是 String 类型的字符串 s1,该函数说明,只能将 &str 类型的字符串切片添加到 String 类型的 s1 上,然后返回一个新的 String 类型,所以 let s3 = s1 + &s2; 就很好解释了,将 String 类型的 s1 与 &str 类型的 s2 进行相加,最终得到 String 类型的 s3。
由此可推,以下代码也是合法的:
let s1 = String::from("tic");
let s2 = String::from("tac");
let s3 = String::from("toe");
// String = String + &str + &str + &str + &str
let s = s1 + "-" + &s2 + "-" + &s3;
String + &str返回一个 String,然后再继续跟一个 &str 进行 + 操作,返回一个 String 类型,不断循环,最终生成一个 s,也是 String 类型。
s1 这个变量通过调用 add() 方法后,所有权被转移到 add() 方法里面, add() 方法调用后就被释放了,同时 s1 也被释放了。再使用 s1 就会发生错误。这里涉及到所有权转移(Move)的相关知识。
2、使用 format! 连接字符串
format! 这种方式适用于 String 和 &str 。format! 的用法与 print! 的用法类似,详见格式化输出。
示例代码如下:
fn main() {
let s1 = "hello";
let s2 = String::from("rust");
let s = format!("{} {}!", s1, s2);
println!("{}", s);
}
代码运行结果:
hello rust!
字符串转义
我们可以通过转义的方式 \ 输出 ASCII 和 Unicode 字符。
fn main() {
// 通过 \ + 字符的十六进制表示,转义输出一个字符
let byte_escape = "I'm writing \x52\x75\x73\x74!";
println!("What are you doing\x3F (\\x3F means ?) {}", byte_escape);
// \u 可以输出一个 unicode 字符
let unicode_codepoint = "\u{211D}";
let character_name = "\"DOUBLE-STRUCK CAPITAL R\"";
println!(
"Unicode character {} (U+211D) is called {}",
unicode_codepoint, character_name
);
// 换行了也会保持之前的字符串格式
// 使用\忽略换行符
let long_string = "String literals
can span multiple lines.
The linebreak and indentation here ->\
<- can be escaped too!";
println!("{}", long_string);
}当然,在某些情况下,可能你会希望保持字符串的原样,不要转义:
fn main() {
println!("{}", "hello \\x52\\x75\\x73\\x74");
let raw_str = r"Escapes don't work here: \x3F \u{211D}";
println!("{}", raw_str);
// 如果字符串包含双引号,可以在开头和结尾加 #
let quotes = r#"And then I said: "There is no escape!""#;
println!("{}", quotes);
// 如果字符串中包含 # 号,可以在开头和结尾加多个 # 号,最多加255个,只需保证与字符串中连续 # 号的个数不超过开头和结尾的 # 号的个数即可
let longer_delimiter = r###"A string with "# in it. And even "##!"###;
println!("{}", longer_delimiter);
}操作 UTF-8 字符串
前文提到了几种使用 UTF-8 字符串的方式,下面来一一说明。
字符
如果你想要以 Unicode 字符的方式遍历字符串,最好的办法是使用 chars 方法,例如:
for c in "中国人".chars() {
println!("{}", c);
}
输出如下
中
国
人
字节
这种方式是返回字符串的底层字节数组表现形式:
for b in "中国人".bytes() {
println!("{}", b);
}
输出如下:
228
184
173
229
155
189
228
186
186
获取子串
想要准确的从 UTF-8 字符串中获取子串是较为复杂的事情,例如想要从 holla中国人नमस्ते 这种变长的字符串中取出某一个子串,使用标准库你是做不到的。 你需要在 crates.io 上搜索 utf8 来寻找想要的功能。
可以考虑尝试下这个库:utf8_slice。
字符串深度剖析
那么问题来了,为啥 String 可变,而字符串字面值 str 却不可以?
就字符串字面值来说,我们在编译时就知道其内容,最终字面值文本被直接硬编码进可执行文件中,这使得字符串字面值快速且高效,这主要得益于字符串字面值的不可变性。不幸的是,我们不能为了获得这种性能,而把每一个在编译时大小未知的文本都放进内存中(你也做不到!),因为有的字符串是在程序运行的过程中动态生成的。
对于 String 类型,为了支持一个可变、可增长的文本片段,需要在堆上分配一块在编译时未知大小的内存来存放内容,这些都是在程序运行时完成的:
首先向操作系统请求内存来存放
String对象在使用完成后,将内存释放,归还给操作系统
其中第一部分由 String::from 完成,它创建了一个全新的 String。
重点来了,到了第二部分,就是百家齐放的环节,在有垃圾回收 GC 的语言中,GC 来负责标记并清除这些不再使用的内存对象,这个过程都是自动完成,无需开发者关心,非常简单好用;但是在无 GC 的语言中,需要开发者手动去释放这些内存对象,就像创建对象需要通过编写代码来完成一样,未能正确释放对象造成的后果简直不可估量。
对于 Rust 而言,安全和性能是写到骨子里的核心特性,如果使用 GC,那么会牺牲性能;如果使用手动管理内存,那么会牺牲安全,这该怎么办?为此,Rust 的开发者想出了一个无比惊艳的办法:变量在离开作用域后,就自动释放其占用的内存:
{
let s = String::from("hello"); // 从此处起,s 是有效的
// 使用 s
} // 此作用域已结束,
// s 不再有效,内存被释放
与其它系统编程语言的 free 函数相同,Rust 也提供了一个释放内存的函数: drop,但是不同的是,其它语言要手动调用 free 来释放每一个变量占用的内存,而 Rust 则在变量离开作用域时,自动调用 drop 函数:上面代码中,Rust 在结尾的 } 处自动调用 drop。
其实,在 C++ 中,也有这种概念:Resource Acquisition Is Initialization (RAII)。如果你使用过 RAII 模式的话应该对 Rust 的
drop函数并不陌生。
元组
元组是由多种类型组合到一起形成的,因此它是复合类型,元组的长度是固定的,元组中元素的顺序也是固定的。
可以通过以下语法创建一个元组:
fn main() {
let tup: (i32, f64, u8) = (500, 6.4, 1);
}变量 tup 被绑定了一个元组值 (500, 6.4, 1),该元组的类型是 (i32, f64, u8),看到没?元组是用括号将多个类型组合到一起,简单吧?
可以使用模式匹配或者 . 操作符来获取元组中的值。
用模式匹配解构元组
fn main() {
let tup = (500, 6.4, 1);
let (x, y, z) = tup;
println!("The value of y is: {}", y);
}上述代码首先创建一个元组,然后将其绑定到 tup 上,接着使用 let (x, y, z) = tup; 来完成一次模式匹配,因为元组是 (n1, n2, n3) 形式的,因此我们用一模一样的 (x, y, z) 形式来进行匹配,元组中对应的值会绑定到变量 x, y, z上。这就是解构:用同样的形式把一个复杂对象中的值匹配出来。
用 . 来访问元组
模式匹配可以让我们一次性把元组中的值全部或者部分获取出来,如果只想要访问某个特定元素,那模式匹配就略显繁琐,对此,Rust 提供了 . 的访问方式:
fn main() {
let x: (i32, f64, u8) = (500, 6.4, 1);
let five_hundred = x.0;
let six_point_four = x.1;
let one = x.2;
}和其它语言的数组、字符串一样,元组的索引从 0 开始。
元组的使用示例
元组在函数返回值场景很常用,例如下面的代码,可以使用元组返回多个值:
fn main() {
let s1 = String::from("hello");
let (s2, len) = calculate_length(s1);
println!("The length of '{}' is {}.", s2, len);
}
fn calculate_length(s: String) -> (String, usize) {
let length = s.len(); // len() 返回字符串的长度
(s, length)
}calculate_length 函数接收 s1 字符串的所有权,然后计算字符串的长度,接着把字符串所有权和字符串长度再返回给 s2 和 len 变量。
在其他语言中,可以用结构体来声明一个三维空间中的点,例如 Point(10, 20, 30),虽然使用 Rust 元组也可以做到:(10, 20, 30),但是这样写有个非常重大的缺陷:
不具备任何清晰的含义,在后面,会提到一种与元组类似的结构体,元组结构体,可以解决这个问题。
结构体
上一节中提到需要一个更高级的数据结构来帮助我们更好的抽象问题,结构体 struct 恰恰就是这样的复合数据结构,它是由其它数据类型组合而来。 其它语言也有类似的数据结构,不过可能有不同的名称,例如 object、 record 等。
结构体跟之前讲过的元组有些相像:都是由多种类型组合而成。但是与元组不同的是,结构体可以为内部的每个字段起一个富有含义的名称。因此结构体更加灵活更加强大,你无需依赖这些字段的顺序来访问和解析它们。
结构体语法
天下无敌的剑士往往也因为他有一柄无双之剑,既然结构体这么强大,那么我们就需要给它配套一套强大的语法,让用户能更好的驾驭。
定义结构体
一个结构体由几部分组成:
通过关键字
struct定义一个清晰明确的结构体
名称几个有名字的结构体
字段
例如, 以下结构体定义了某网站的用户:
struct User {
active: bool,
username: String,
email: String,
sign_in_count: u64,
}
该结构体名称是 User,拥有 4 个字段,且每个字段都有对应的字段名及类型声明,例如 username 代表了用户名,是一个可变的 String 类型。
创建结构体实例
为了使用上述结构体,我们需要创建 User 结构体的实例:
let user1 = User {
email: String::from("someone@example.com"),
username: String::from("someusername123"),
active: true,
sign_in_count: 1,
};
有几点值得注意:
初始化实例时,每个字段都需要进行初始化
初始化时的字段顺序不需要和结构体定义时的顺序一致
访问结构体字段
通过 . 操作符即可访问结构体实例内部的字段值,也可以修改它们:
let mut user1 = User {
email: String::from("someone@example.com"),
username: String::from("someusername123"),
active: true,
sign_in_count: 1,
};
user1.email = String::from("anotheremail@example.com");
需要注意的是,必须要将结构体实例声明为可变的,才能修改其中的字段,Rust 不支持将某个结构体某个字段标记为可变。
简化结构体创建
下面的函数类似一个构建函数,返回了 User 结构体的实例:
fn build_user(email: String, username: String) -> User {
User {
email: email,
username: username,
active: true,
sign_in_count: 1,
}
}
它接收两个字符串参数: email 和 username,然后使用它们来创建一个 User 结构体,并且返回。可以注意到这两行: email: email 和 username: username,非常的扎眼,因为实在有些啰嗦,如果你从 TypeScript 过来,肯定会鄙视 Rust 一番,不过好在,它也不是无可救药:
fn build_user(email: String, username: String) -> User {
User {
email,
username,
active: true,
sign_in_count: 1,
}
}
如上所示,当函数参数和结构体字段同名时,可以直接使用缩略的方式进行初始化,跟 TypeScript 中一模一样。
结构体更新语法
在实际场景中,有一种情况很常见:根据已有的结构体实例,创建新的结构体实例,例如根据已有的 user1 实例来构建 user2:
let user2 = User {
active: user1.active,
username: user1.username,
email: String::from("another@example.com"),
sign_in_count: user1.sign_in_count,
};
老话重提,如果你从 TypeScript 过来,肯定觉得啰嗦爆了:竟然手动把 user1 的三个字段逐个赋值给 user2,好在 Rust 为我们提供了 结构体更新语法:
let user2 = User {
email: String::from("another@example.com"),
..user1
};
因为 user2 仅仅在 email 上与 user1 不同,因此我们只需要对 email 进行赋值,剩下的通过结构体更新语法 ..user1 即可完成。
.. 语法表明凡是我们没有显式声明的字段,全部从 user1 中自动获取。需要注意的是 ..user1 必须在结构体的尾部使用。
结构体更新语法跟赋值语句
=非常相像,因此在上面代码中,user1的部分字段所有权被转移到user2中:username字段发生了所有权转移,作为结果,user1无法再被使用。聪明的读者肯定要发问了:明明有三个字段进行了自动赋值,为何只有
username发生了所有权转移?仔细回想一下所有权那一节的内容,我们提到了
Copy特征:实现了Copy特征的类型无需所有权转移,可以直接在赋值时进行 数据拷贝,其中bool和u64类型就实现了Copy特征,因此active和sign_in_count字段在赋值给user2时,仅仅发生了拷贝,而不是所有权转移。值得注意的是:
username所有权被转移给了user2,导致了user1无法再被使用,但是并不代表user1内部的其它字段不能被继续使用,例如:
let user1 = User {
email: String::from("someone@example.com"),
username: String::from("someusername123"),
active: true,
sign_in_count: 1,
};
let user2 = User {
active: user1.active,
username: user1.username,
email: String::from("another@example.com"),
sign_in_count: user1.sign_in_count,
};
println!("{}", user1.active);
// 下面这行会报错
println!("{:?}", user1);
结构体的内存排列
先来看以下代码:
#[derive(Debug)]
struct File {
name: String,
data: Vec<u8>,
}
fn main() {
let f1 = File {
name: String::from("f1.txt"),
data: Vec::new(),
};
let f1_name = &f1.name;
let f1_length = &f1.data.len();
println!("{:?}", f1);
println!("{} is {} bytes long", f1_name, f1_length);
}上面定义的 File 结构体在内存中的排列如下图所示: 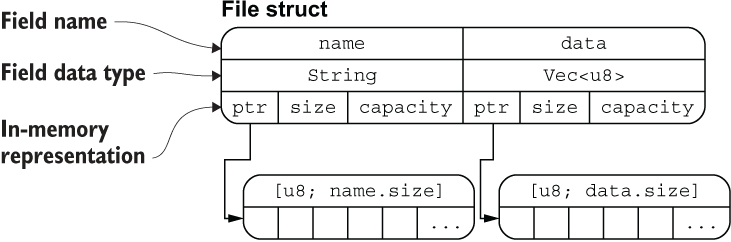
从图中可以清晰地看出 File 结构体两个字段 name 和 data 分别拥有底层两个 [u8] 数组的所有权(String 类型的底层也是 [u8] 数组),通过 ptr 指针指向底层数组的内存地址,这里你可以把 ptr 指针理解为 Rust 中的引用类型。
该图片也侧面印证了:把结构体中具有所有权的字段转移出去后,将无法再访问该字段,但是可以正常访问其它的字段。
元组结构体(Tuple Struct)
结构体必须要有名称,但是结构体的字段可以没有名称,这种结构体长得很像元组,因此被称为元组结构体,例如:
struct Color(i32, i32, i32);
struct Point(i32, i32, i32);
let black = Color(0, 0, 0);
let origin = Point(0, 0, 0);
元组结构体在你希望有一个整体名称,但是又不关心里面字段的名称时将非常有用。例如上面的 Point 元组结构体,众所周知 3D 点是 (x, y, z) 形式的坐标点,因此我们无需再为内部的字段逐一命名为:x, y, z。
单元结构体(Unit-like Struct)
还记得之前讲过的基本没啥用的单元类型吧?单元结构体就跟它很像,没有任何字段和属性,但是好在,它还挺有用。
如果你定义一个类型,但是不关心该类型的内容,只关心它的行为时,就可以使用 单元结构体:
struct AlwaysEqual;
let subject = AlwaysEqual;
// 我们不关心 AlwaysEqual 的字段数据,只关心它的行为,因此将它声明为单元结构体,然后再为它实现某个特征
impl SomeTrait for AlwaysEqual {
}
结构体数据的所有权
在之前的 User 结构体的定义中,有一处细节:我们使用了自身拥有所有权的 String 类型而不是基于引用的 &str 字符串切片类型。这是一个有意而为之的选择:因为我们想要这个结构体拥有它所有的数据,而不是从其它地方借用数据。
你也可以让 User 结构体从其它对象借用数据,不过这么做,就需要引入生命周期(lifetimes)这个新概念(也是一个复杂的概念),简而言之,生命周期能确保结构体的作用范围要比它所借用的数据的作用范围要小。
总之,如果你想在结构体中使用一个引用,就必须加上生命周期,否则就会报错:
struct User {
username: &str,
email: &str,
sign_in_count: u64,
active: bool,
}
fn main() {
let user1 = User {
email: "someone@example.com",
username: "someusername123",
active: true,
sign_in_count: 1,
};
}编译器会抱怨它需要生命周期标识符:
error[E0106]: missing lifetime specifier
--> src/main.rs:2:15
|
2 | username: &str,
| ^ expected named lifetime parameter // 需要一个生命周期
|
help: consider introducing a named lifetime parameter // 考虑像下面的代码这样引入一个生命周期
|
1 ~ struct User<'a> {
2 ~ username: &'a str,
|
error[E0106]: missing lifetime specifier
--> src/main.rs:3:12
|
3 | email: &str,
| ^ expected named lifetime parameter
|
help: consider introducing a named lifetime parameter
|
1 ~ struct User<'a> {
2 | username: &str,
3 ~ email: &'a str,
|
未来在生命周期中会讲到如何修复这个问题以便在结构体中存储引用,不过在那之前,我们会避免在结构体中使用引用类型。
使用 #[derive(Debug)] 来打印结构体的信息
在前面的代码中我们使用 #[derive(Debug)] 对结构体进行了标记,这样才能使用 println!("{:?}", s); 的方式对其进行打印输出,如果不加,看看会发生什么:
struct Rectangle {
width: u32,
height: u32,
}
fn main() {
let rect1 = Rectangle {
width: 30,
height: 50,
};
println!("rect1 is {}", rect1);
}首先可以观察到,上面使用了 {} 而不是之前的 {:?},运行后报错:
error[E0277]: `Rectangle` doesn't implement `std::fmt::Display`
提示我们结构体 Rectangle 没有实现 Display 特征,这是因为如果我们使用 {} 来格式化输出,那对应的类型就必须实现 Display 特征,以前学习的基本类型,都默认实现了该特征:
fn main() {
let v = 1;
let b = true;
println!("{}, {}", v, b);
}上面代码不会报错,那么结构体为什么不默认实现 Display 特征呢?原因在于结构体较为复杂,例如考虑以下问题:你想要逗号对字段进行分割吗?需要括号吗?加在什么地方?所有的字段都应该显示?类似的还有很多,由于这种复杂性,Rust 不希望猜测我们想要的是什么,而是把选择权交给我们自己来实现:如果要用 {} 的方式打印结构体,那就自己实现 Display 特征。
接下来继续阅读报错:
= help: the trait `std::fmt::Display` is not implemented for `Rectangle`
= note: in format strings you may be able to use `{:?}` (or {:#?} for pretty-print) instead
上面提示我们使用 {:?} 来试试,这个方式我们在本文的前面也见过,下面来试试:
println!("rect1 is {:?}", rect1);
可是依然无情报错了:
error[E0277]: `Rectangle` doesn't implement `Debug`
好在,聪明的编译器又一次给出了提示:
= help: the trait `Debug` is not implemented for `Rectangle`
= note: add `#[derive(Debug)]` to `Rectangle` or manually `impl Debug for Rectangle`
让我们实现 Debug 特征,Oh No,就是不想实现 Display 特征,才用的 {:?},怎么又要实现 Debug,但是仔细看,提示中有一行: add #[derive(Debug)] to Rectangle, 哦?这不就是我们前文一直在使用的吗?
首先,Rust 默认不会为我们实现 Debug,为了实现,有两种方式可以选择:
手动实现
使用
derive派生实现
后者简单的多,但是也有限制,具体见附录 D,这里我们就不再深入讲解,来看看该如何使用:
#[derive(Debug)]
struct Rectangle {
width: u32,
height: u32,
}
fn main() {
let rect1 = Rectangle {
width: 30,
height: 50,
};
println!("rect1 is {:?}", rect1);
}此时运行程序,就不再有错误,输出如下:
$ cargo run
rect1 is Rectangle { width: 30, height: 50 }
这个输出格式看上去也不赖嘛,虽然未必是最好的。这种格式是 Rust 自动为我们提供的实现,看上基本就跟结构体的定义形式一样。
当结构体较大时,我们可能希望能够有更好的输出表现,此时可以使用 {:#?} 来替代 {:?},输出如下:
rect1 is Rectangle {
width: 30,
height: 50,
}
此时结构体的输出跟我们创建时候的代码几乎一模一样了!当然,如果大家还是不满足,那最好还是自己实现 Display 特征,以向用户更美的展示你的私藏结构体。关于格式化输出的更多内容,我们强烈推荐看看这个章节。
还有一个简单的输出 debug 信息的方法,那就是使用 dbg! 宏,它会拿走表达式的所有权,然后打印出相应的文件名、行号等 debug 信息,当然还有我们需要的表达式的求值结果。除此之外,它最终还会把表达式值的所有权返回!
dbg!输出到标准错误输出stderr,而println!输出到标准输出stdout。
下面的例子中清晰的展示了 dbg! 如何在打印出信息的同时,还把表达式的值赋给了 width:
#[derive(Debug)]
struct Rectangle {
width: u32,
height: u32,
}
fn main() {
let scale = 2;
let rect1 = Rectangle {
width: dbg!(30 * scale),
height: 50,
};
dbg!(&rect1);
}最终的 debug 输出如下:
$ cargo run
[src/main.rs:10] 30 * scale = 60
[src/main.rs:14] &rect1 = Rectangle {
width: 60,
height: 50,
}
可以看到,我们想要的 debug 信息几乎都有了:代码所在的文件名、行号、表达式以及表达式的值,简直完美!
枚举
枚举(enum 或 enumeration)允许你通过列举可能的成员来定义一个枚举类型,例如扑克牌花色:
enum PokerSuit {
Clubs,
Spades,
Diamonds,
Hearts,
}
如果在此之前你没有在其它语言中使用过枚举,那么可能需要花费一些时间来理解这些概念,一旦上手,就会发现枚举的强大,甚至对它爱不释手,枚举虽好,可不要滥用哦。
再回到之前创建的 PokerSuit,扑克总共有四种花色,而这里我们枚举出所有的可能值,这也正是 枚举 名称的由来。
任何一张扑克,它的花色肯定会落在四种花色中,而且也只会落在其中一个花色上,这种特性非常适合枚举的使用,因为枚举值只可能是其中某一个成员。抽象来看,四种花色尽管是不同的花色,但是它们都是扑克花色这个概念,因此当某个函数处理扑克花色时,可以把它们当作相同的类型进行传参。
细心的读者应该注意到,我们对之前的 枚举类型 和 枚举值 进行了重点标注,这是因为对于新人来说容易混淆相应的概念,总而言之: 枚举类型是一个类型,它会包含所有可能的枚举成员,而枚举值是该类型中的具体某个成员的实例。
枚举值
现在来创建 PokerSuit 枚举类型的两个成员实例:
let heart = PokerSuit::Hearts;
let diamond = PokerSuit::Diamonds;
我们通过 :: 操作符来访问 PokerSuit 下的具体成员,从代码可以清晰看出,heart 和 diamond 都是 PokerSuit 枚举类型的,接着可以定义一个函数来使用它们:
fn main() {
let heart = PokerSuit::Hearts;
let diamond = PokerSuit::Diamonds;
print_suit(heart);
print_suit(diamond);
}
fn print_suit(card: PokerSuit) {
// 需要在定义 enum PokerSuit 的上面添加上 #[derive(Debug)],否则会报 card 没有实现 Debug
println!("{:?}",card);
}print_suit 函数的参数类型是 PokerSuit,因此我们可以把 heart 和 diamond 传给它,虽然 heart 是基于 PokerSuit 下的 Hearts 成员实例化的,但是它是货真价实的 PokerSuit 枚举类型。
接下来,我们想让扑克牌变得更加实用,那么需要给每张牌赋予一个值:A(1)-K(13),这样再加上花色,就是一张真实的扑克牌了,例如红心 A。
目前来说,枚举值还不能带有值,因此先用结构体来实现:
enum PokerSuit {
Clubs,
Spades,
Diamonds,
Hearts,
}
struct PokerCard {
suit: PokerSuit,
value: u8
}
fn main() {
let c1 = PokerCard {
suit: PokerSuit::Clubs,
value: 1,
};
let c2 = PokerCard {
suit: PokerSuit::Diamonds,
value: 12,
};
}这段代码很好的完成了它的使命,通过结构体 PokerCard 来代表一张牌,结构体的 suit 字段表示牌的花色,类型是 PokerSuit 枚举类型,value 字段代表扑克牌的数值。
可以吗?可以!好吗?说实话,不咋地,因为还有简洁得多的方式来实现:
enum PokerCard {
Clubs(u8),
Spades(u8),
Diamonds(u8),
Hearts(u8),
}
fn main() {
let c1 = PokerCard::Spades(5);
let c2 = PokerCard::Diamonds(13);
}直接将数据信息关联到枚举成员上,省去近一半的代码,这种实现是不是更优雅?
不仅如此,同一个枚举类型下的不同成员还能持有不同的数据类型,例如让某些花色打印 1-13 的字样,另外的花色打印上 A-K 的字样:
enum PokerCard {
Clubs(u8),
Spades(u8),
Diamonds(char),
Hearts(char),
}
fn main() {
let c1 = PokerCard::Spades(5);
let c2 = PokerCard::Diamonds('A');
}回想一下,遇到这种不同类型的情况,再用我们之前的结构体实现方式,可行吗?也许可行,但是会复杂很多。
再来看一个来自标准库中的例子:
struct Ipv4Addr {
// --snip--
}
struct Ipv6Addr {
// --snip--
}
enum IpAddr {
V4(Ipv4Addr),
V6(Ipv6Addr),
}
这个例子跟我们之前的扑克牌很像,只不过枚举成员包含的类型更复杂了,变成了结构体:分别通过 Ipv4Addr 和 Ipv6Addr 来定义两种不同的 IP 数据。
从这些例子可以看出,任何类型的数据都可以放入枚举成员中:例如字符串、数值、结构体甚至另一个枚举。
增加一些挑战?先看以下代码:
enum Message {
Quit,
Move { x: i32, y: i32 },
Write(String),
ChangeColor(i32, i32, i32),
}
fn main() {
let m1 = Message::Quit;
let m2 = Message::Move{x:1,y:1};
let m3 = Message::ChangeColor(255,255,0);
}该枚举类型代表一条消息,它包含四个不同的成员:
Quit没有任何关联数据Move包含一个匿名结构体Write包含一个String字符串ChangeColor包含三个i32
当然,我们也可以用结构体的方式来定义这些消息:
struct QuitMessage; // 单元结构体
struct MoveMessage {
x: i32,
y: i32,
}
struct WriteMessage(String); // 元组结构体
struct ChangeColorMessage(i32, i32, i32); // 元组结构体
由于每个结构体都有自己的类型,因此我们无法在需要同一类型的地方进行使用,例如某个函数它的功能是接受消息并进行发送,那么用枚举的方式,就可以接收不同的消息,但是用结构体,该函数无法接受 4 个不同的结构体作为参数。
而且从代码规范角度来看,枚举的实现更简洁,代码内聚性更强,不像结构体的实现,分散在各个地方。
同一化类型
最后,再用一个实际项目中的简化片段,来结束枚举类型的语法学习。
例如我们有一个 WEB 服务,需要接受用户的长连接,假设连接有两种:TcpStream 和 TlsStream,但是我们希望对这两个连接的处理流程相同,也就是用同一个函数来处理这两个连接,代码如下:
fn new (stream: TcpStream) {
let mut s = stream;
if tls {
s = negotiate_tls(stream)
}
// websocket是一个WebSocket<TcpStream>或者
// WebSocket<native_tls::TlsStream<TcpStream>>类型
websocket = WebSocket::from_raw_socket(
s, ......)
}
此时,枚举类型就能帮上大忙:
enum Websocket {
Tcp(Websocket<TcpStream>),
Tls(Websocket<native_tls::TlsStream<TcpStream>>),
}
Option 枚举用于处理空值
在其它编程语言中,往往都有一个 null 关键字,该关键字用于表明一个变量当前的值为空(不是零值,例如整型的零值是 0),也就是不存在值。当你对这些 null 进行操作时,例如调用一个方法,就会直接抛出 null 异常,导致程序的崩溃,因此我们在编程时需要格外的小心去处理这些 null 空值。
Tony Hoare,
null的发明者,曾经说过一段非常有名的话:我称之为我十亿美元的错误。当时,我在使用一个面向对象语言设计第一个综合性的面向引用的类型系统。我的目标是通过编译器的自动检查来保证所有引用的使用都应该是绝对安全的。不过在设计过程中,我未能抵抗住诱惑,引入了空引用的概念,因为它非常容易实现。就是因为这个决策,引发了无数错误、漏洞和系统崩溃,在之后的四十多年中造成了数十亿美元的苦痛和伤害。
尽管如此,空值的表达依然非常有意义,因为空值表示当前时刻变量的值是缺失的。有鉴于此,Rust 吸取了众多教训,决定抛弃 null,而改为使用 Option 枚举变量来表述这种结果。
Option 枚举包含两个成员,一个成员表示含有值:Some(T), 另一个表示没有值:None,定义如下:
enum Option<T> {
Some(T),
None,
}
其中 T 是泛型参数,Some(T)表示该枚举成员的数据类型是 T,换句话说,Some 可以包含任何类型的数据。
Option<T> 枚举是如此有用以至于它被包含在了 prelude(prelude 属于 Rust 标准库,Rust 会将最常用的类型、函数等提前引入其中,省得我们再手动引入)之中,你不需要将其显式引入作用域。另外,它的成员 Some 和 None 也是如此,无需使用 Option:: 前缀就可直接使用 Some 和 None。总之,不能因为 Some(T) 和 None 中没有 Option:: 的身影,就否认它们是 Option 下的卧龙凤雏。
再来看以下代码:
let some_number = Some(5);
let some_string = Some("a string");
let absent_number: Option<i32> = None;
如果使用 None 而不是 Some,需要告诉 Rust Option<T> 是什么类型的,因为编译器只通过 None 值无法推断出 Some 成员保存的值的类型。
当有一个 Some 值时,我们就知道存在一个值,而这个值保存在 Some 中。当有个 None 值时,在某种意义上,它跟空值具有相同的意义:并没有一个有效的值。那么,Option<T> 为什么就比空值要好呢?
简而言之,因为 Option<T> 和 T(这里 T 可以是任何类型)是不同的类型,例如,这段代码不能编译,因为它尝试将 Option<i8>(Option<T>) 与 i8(T) 相加:
let x: i8 = 5;
let y: Option<i8> = Some(5);
let sum = x + y;
如果运行这些代码,将得到类似这样的错误信息:
error[E0277]: the trait bound `i8: std::ops::Add<std::option::Option<i8>>` is
not satisfied
-->
|
5 | let sum = x + y;
| ^ no implementation for `i8 + std::option::Option<i8>`
|
很好!事实上,错误信息意味着 Rust 不知道该如何将 Option<i8> 与 i8 相加,因为它们的类型不同。当在 Rust 中拥有一个像 i8 这样类型的值时,编译器确保它总是有一个有效的值,我们可以放心使用而无需做空值检查。只有当使用 Option<i8>(或者任何用到的类型)的时候才需要担心可能没有值,而编译器会确保我们在使用值之前处理了为空的情况。
换句话说,在对 Option<T> 进行 T 的运算之前必须将其转换为 T。通常这能帮助我们捕获到空值最常见的问题之一:期望某值不为空但实际上为空的情况。
不再担心会错误地使用一个空值,会让你对代码更加有信心。为了拥有一个可能为空的值,你必须要显式的将其放入对应类型的 Option<T> 中。接着,当使用这个值时,必须明确的处理值为空的情况。只要一个值不是 Option<T> 类型,你就 可以 安全的认定它的值不为空。这是 Rust 的一个经过深思熟虑的设计决策,来限制空值的泛滥以增加 Rust 代码的安全性。
那么当有一个 Option<T> 的值时,如何从 Some 成员中取出 T 的值来使用它呢?Option<T> 枚举拥有大量用于各种情况的方法:你可以查看它的文档。熟悉 Option<T> 的方法将对你的 Rust 之旅非常有用。
总的来说,为了使用 Option<T> 值,需要编写处理每个成员的代码。你想要一些代码只当拥有 Some(T) 值时运行,允许这些代码使用其中的 T。也希望一些代码在值为 None 时运行,这些代码并没有一个可用的 T 值。match 表达式就是这么一个处理枚举的控制流结构:它会根据枚举的成员运行不同的代码,这些代码可以使用匹配到的值中的数据。
这里先简单看一下 match 的大致模样,在模式匹配中,我们会详细讲解:
fn plus_one(x: Option<i32>) -> Option<i32> {
match x {
None => None,
Some(i) => Some(i + 1),
}
}
let five = Some(5);
let six = plus_one(five);
let none = plus_one(None);
plus_one 通过 match 来处理不同 Option 的情况。
数组
在日常开发中,使用最广的数据结构之一就是数组,在 Rust 中,最常用的数组有两种,第一种是速度很快但是长度固定的 array,第二种是可动态增长的但是有性能损耗的 Vector,在这里,我们称 array 为数组,Vector 为动态数组。
不知道你们发现没,这两个数组的关系跟 &str 与 String 的关系很像,前者是长度固定的字符串切片,后者是可动态增长的字符串。其实,在 Rust 中无论是 String 还是 Vector,它们都是 Rust 的高级类型:集合类型,在后面会有详细介绍。
在这里,我们的重点还是放在数组 array 上。数组的具体定义很简单:将多个类型相同的元素依次组合在一起,就是一个数组。结合上面的内容,可以得出数组的三要素:
长度固定
元素必须有相同的类型
依次线性排列
这里再啰嗦一句,我们这里说的数组是 Rust 的基本类型,是固定长度的,这点与其他编程语言不同,其它编程语言的数组往往是可变长度的,与 Rust 中的动态数组 Vector 类似,希望读者大大牢记此点。
创建数组
在 Rust 中,数组是这样定义的:
fn main() {
let a = [1, 2, 3, 4, 5];
}数组语法跟 JavaScript 很像,也跟大多数编程语言很像。由于它的元素类型大小固定,且长度也是固定,因此数组 array 是存储在栈上,性能也会非常优秀。与此对应,动态数组 Vector 是存储在堆上,因此长度可以动态改变。当你不确定是使用数组还是动态数组时,那就应该使用后者,具体见动态数组 Vector。
举个例子,在需要知道一年中各个月份名称的程序中,你很可能希望使用的是数组而不是动态数组。因为月份是固定的,它总是只包含 12 个元素:
let months = ["January", "February", "March", "April", "May", "June", "July",
"August", "September", "October", "November", "December"];
在一些时候,还需要为数组声明类型,如下所示:
let a: [i32; 5] = [1, 2, 3, 4, 5];
这里,数组类型是通过方括号语法声明,i32 是元素类型,分号后面的数字 5 是数组长度,数组类型也从侧面说明了数组的元素类型要统一,长度要固定。
还可以使用下面的语法初始化一个某个值重复出现 N 次的数组:
let a = [3; 5];
a 数组包含 5 个元素,这些元素的初始化值为 3,聪明的读者已经发现,这种语法跟数组类型的声明语法其实是保持一致的:[3; 5] 和 [类型; 长度]。
在元素重复的场景,这种写法要简单的多,否则你就得疯狂敲击键盘:let a = [3, 3, 3, 3, 3];,不过老板可能很喜欢你的这种疯狂编程的状态。
访问数组元素
因为数组是连续存放元素的,因此可以通过索引的方式来访问存放其中的元素:
fn main() {
let a = [9, 8, 7, 6, 5];
let first = a[0]; // 获取a数组第一个元素
let second = a[1]; // 获取第二个元素
}与许多语言类似,数组的索引下标是从 0 开始的。此处,first 获取到的值是 9,second 是 8。
越界访问
如果使用超出数组范围的索引访问数组元素,会怎么样?下面是一个接收用户的控制台输入,然后将其作为索引访问数组元素的例子:
use std::io;
fn main() {
let a = [1, 2, 3, 4, 5];
println!("Please enter an array index.");
let mut index = String::new();
// 读取控制台的输出
io::stdin()
.read_line(&mut index)
.expect("Failed to read line");
let index: usize = index
.trim()
.parse()
.expect("Index entered was not a number");
let element = a[index];
println!(
"The value of the element at index {} is: {}",
index, element
);
}使用 cargo run 来运行代码,因为数组只有 5 个元素,如果我们试图输入 5 去访问第 6 个元素,则会访问到不存在的数组元素,最终程序会崩溃退出:
Please enter an array index.
5
thread 'main' panicked at 'index out of bounds: the len is 5 but the index is 5', src/main.rs:19:19
note: run with `RUST_BACKTRACE=1` environment variable to display a backtrace
这就是数组访问越界,访问了数组中不存在的元素,导致 Rust 运行时错误。程序因此退出并显示错误消息,未执行最后的 println! 语句。
当你尝试使用索引访问元素时,Rust 将检查你指定的索引是否小于数组长度。如果索引大于或等于数组长度,Rust 会出现 panic。这种检查只能在运行时进行,比如在上面这种情况下,编译器无法在编译期知道用户运行代码时将输入什么值。
这种就是 Rust 的安全特性之一。在很多系统编程语言中,并不会检查数组越界问题,你会访问到无效的内存地址获取到一个风马牛不相及的值,最终导致在程序逻辑上出现大问题,而且这种问题会非常难以检查。
数组元素为非基础类型
学习了上面的知识,很多朋友肯定觉得已经学会了 Rust 的数组类型,但现实会给我们一记重锤,实际开发中还会碰到一种情况,就是数组元素是非基本类型的,这时候大家一定会这样写。
let array = [String::from("rust is good!"); 8];
println!("{:#?}", array);
然后你会惊喜的得到编译错误。
error[E0277]: the trait bound `String: std::marker::Copy` is not satisfied
--> src/main.rs:7:18
|
7 | let array = [String::from("rust is good!"); 8];
| ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^ the trait `std::marker::Copy` is not implemented for `String`
|
= note: the `Copy` trait is required because this value will be copied for each element of the array
有些还没有看过特征的小伙伴,有可能不太明白这个报错,不过这个目前可以不提,我们就拿之前所学的所有权知识,就可以思考明白,前面几个例子都是 Rust 的基本类型,而基本类型在 Rust 中赋值是以 Copy 的形式,这时候你就懂了吧,let array=[3;5]底层就是不断的Copy出来的,但很可惜复杂类型都没有深拷贝,只能一个个创建。
接着就有小伙伴会这样写。
let array = [String::from("rust is good!"),String::from("rust is good!"),String::from("rust is good!")];
println!("{:#?}", array);
作为一个追求极致完美的Rust开发者,怎么能容忍上面这么难看的代码存在!
正确的写法,应该调用std::array::from_fn
let array: [String; 8] = std::array::from_fn(|_i| String::from("rust is good!"));
println!("{:#?}", array);
数组切片
在之前的内容,我们有讲到 切片 这个概念,它允许你引用集合中的部分连续片段,而不是整个集合,对于数组也是,数组切片允许我们引用数组的一部分:
let a: [i32; 5] = [1, 2, 3, 4, 5];
let slice: &[i32] = &a[1..3];
assert_eq!(slice, &[2, 3]);
上面的数组切片 slice 的类型是&[i32],与之对比,数组的类型是[i32;5],简单总结下切片的特点:
切片的长度可以与数组不同,并不是固定的,而是取决于你使用时指定的起始和结束位置
创建切片的代价非常小,因为切片只是针对底层数组的一个引用
切片类型 [T] 拥有不固定的大小,而切片引用类型 &[T] 则具有固定的大小,因为 Rust 很多时候都需要固定大小数据类型,因此 &[T] 更有用,
&str字符串切片也同理
总结
最后,让我们以一个综合性使用数组的例子,来结束本章节的学习:
fn main() {
// 编译器自动推导出one的类型
let one = [1, 2, 3];
// 显式类型标注
let two: [u8; 3] = [1, 2, 3];
let blank1 = [0; 3];
let blank2: [u8; 3] = [0; 3];
// arrays是一个二维数组,其中每一个元素都是一个数组,元素类型是[u8; 3]
let arrays: [[u8; 3]; 4] = [one, two, blank1, blank2];
// 借用arrays的元素用作循环中
for a in &arrays {
print!("{:?}: ", a);
// 将a变成一个迭代器,用于循环
// 你也可以直接用for n in a {}来进行循环
for n in a.iter() {
print!("\t{} + 10 = {}", n, n+10);
}
let mut sum = 0;
// 0..a.len,是一个 Rust 的语法糖,其实就等于一个数组,元素是从0,1,2一直增加到到a.len-1
for i in 0..a.len() {
sum += a[i];
}
println!("\t({:?} = {})", a, sum);
}
}做个总结,数组虽然很简单,但是其实还是存在几个要注意的点:
数组类型容易跟数组切片混淆,[T;n] 描述了一个数组的类型,而 [T] 描述了切片的类型, 因为切片是运行期的数据结构,它的长度无法在编译期得知,因此不能用 [T;n] 的形式去描述
[u8; 3]和[u8; 4]是不同的类型,数组的长度也是类型的一部分在实际开发中,使用最多的是数组切片[T],我们往往通过引用的方式去使用
&[T],因为后者有固定的类型大小
至此,关于数据类型部分,我们已经全部学完了,对于 Rust 学习而言,我们也迈出了坚定的第一步,后面将开始更高级特性的学习。
