Rust 每个值都有其确切的数据类型,总的来说可以分为两类:基本类型和复合类型。 基本类型意味着它们往往是一个最小化原子类型,无法解构为其它类型(一般意义上来说),由以下组成:
数值类型:有符号整数 (
i8,i16,i32,i64,isize)、 无符号整数 (u8,u16,u32,u64,usize) 、浮点数 (f32,f64)、以及有理数、复数字符串:字符串字面量和字符串切片
&str布尔类型:
true和false字符类型:表示单个 Unicode 字符,存储为 4 个字节
单元类型:即
(),其唯一的值也是()
类型推导与标注
Rust 是一门静态类型语言,也就是编译器必须在编译期知道我们所有变量的类型,但这不意味着你需要为每个变量指定类型,因为 Rust 编译器很聪明,它可以根据变量的值和上下文中的使用方式来自动推导出变量的类型,同时编译器也不够聪明,在某些情况下,它无法推导出变量类型,需要手动去给予一个类型标注,关于这一点在 Rust 语言初印象 中有过展示。
来看段代码:
let guess = "42".parse().expect("Not a number!");
先忽略 .parse().expect.. 部分,这段代码的目的是将字符串 "42" 进行解析,而编译器在这里无法推导出我们想要的类型:整数?浮点数?字符串?因此编译器会报错:
$ cargo build
Compiling no_type_annotations v0.1.0 (file:///projects/no_type_annotations)
error[E0282]: type annotations needed
--> src/main.rs:2:9
|
2 | let guess = "42".parse().expect("Not a number!");
| ^^^^^ consider giving `guess` a type
因此我们需要提供给编译器更多的信息,例如给 guess 变量一个显式的类型标注:let guess: i32 = ... 或者 "42".parse::<i32>()。
数值类型
Rust 使用一个相对传统的语法来创建整数(1,2,...)和浮点数(1.0,1.1,...)。整数、浮点数的运算和你在其它语言上见过的一致,都是通过常见的运算符来完成。
不仅仅是数值类型,Rust 也允许在复杂类型上定义运算符,例如在自定义类型上定义
+运算符,这种行为被称为运算符重载,Rust 具体支持的可重载运算符见附录 B。
整数类型
整数是没有小数部分的数字。之前使用过的 i32 类型,表示有符号的 32 位整数( i 是英文单词 integer 的首字母,与之相反的是 u,代表无符号 unsigned 类型)。下表显示了 Rust 中的内置的整数类型:
类型定义的形式统一为:有无符号 + 类型大小(位数)。无符号数表示数字只能取正数和 0,而有符号则表示数字可以取正数、负数还有 0。有符号数字以补码形式存储。
每个有符号类型规定的数字范围是 -(2n - 1) ~ 2n - 1 - 1,其中 n 是该定义形式的位长度。因此 i8 可存储数字范围是 -(27) ~ 27 - 1,即 -128 ~ 127。无符号类型可以存储的数字范围是 0 ~ 2n - 1,所以 u8 能够存储的数字为 0 ~ 28 - 1,即 0 ~ 255。
此外,isize 和 usize 类型取决于程序运行的计算机 CPU 类型: 若 CPU 是 32 位的,则这两个类型是 32 位的,同理,若 CPU 是 64 位,那么它们则是 64 位。
整型字面量可以用下表的形式书写:
Rust 整型默认使用 i32,例如 let i = 1,那 i 就是 i32 类型,因此你可以首选它,同时该类型也往往是性能最好的。isize 和 usize 的主要应用场景是用作集合的索引。
整型溢出
假设有一个 u8 ,它可以存放从 0 到 255 的值。那么当你将其修改为范围之外的值,比如 256,则会发生整型溢出。关于这一行为 Rust 有一些有趣的规则:当在 debug 模式编译时,Rust 会检查整型溢出,若存在这些问题,则使程序在编译时 panic(崩溃,Rust 使用这个术语来表明程序因错误而退出)。
在当使用 --release 参数进行 release 模式构建时,Rust 不检测溢出。相反,当检测到整型溢出时,Rust 会按照补码循环溢出(two’s complement wrapping)的规则处理。简而言之,大于该类型最大值的数值会被补码转换成该类型能够支持的对应数字的最小值。比如在 u8 的情况下,256 变成 0,257 变成 1,依此类推。程序不会 panic,但是该变量的值可能不是你期望的值。依赖这种默认行为的代码都应该被认为是错误的代码。
要显式处理可能的溢出,可以使用标准库针对原始数字类型提供的这些方法:
使用
wrapping_*方法在所有模式下都按照补码循环溢出规则处理,例如wrapping_add如果使用
checked_*方法时发生溢出,则返回None值使用
overflowing_*方法返回该值和一个指示是否存在溢出的布尔值使用
saturating_*方法,可以限定计算后的结果不超过目标类型的最大值或低于最小值,例如:
assert_eq!(100u8.saturating_add(1), 101);
assert_eq!(u8::MAX.saturating_add(127), u8::MAX);
下面是一个演示wrapping_*方法的示例:
fn main() {
let a : u8 = 255;
let b = a.wrapping_add(20);
println!("{}", b); // 19
}浮点类型
浮点类型数字 是带有小数点的数字,在 Rust 中浮点类型数字也有两种基本类型: f32 和 f64,分别为 32 位和 64 位大小。默认浮点类型是 f64,在现代的 CPU 中它的速度与 f32 几乎相同,但精度更高。
下面是一个演示浮点数的示例:
fn main() {
let x = 2.0; // f64
let y: f32 = 3.0; // f32
}浮点数根据 IEEE-754 标准实现。f32 类型是单精度浮点型,f64 为双精度。
浮点数陷阱
浮点数由于底层格式的特殊性,导致了如果在使用浮点数时不够谨慎,就可能造成危险,有两个原因:
浮点数往往是你想要数字的近似表达 浮点数类型是基于二进制实现的,但是我们想要计算的数字往往是基于十进制,例如
0.1在二进制上并不存在精确的表达形式,但是在十进制上就存在。这种不匹配性导致一定的歧义性,更多的,虽然浮点数能代表真实的数值,但是由于底层格式问题,它往往受限于定长的浮点数精度,如果你想要表达完全精准的真实数字,只有使用无限精度的浮点数才行浮点数在某些特性上是反直觉的 例如大家都会觉得浮点数可以进行比较,对吧?是的,它们确实可以使用
>,>=等进行比较,但是在某些场景下,这种直觉上的比较特性反而会害了你。因为f32,f64上的比较运算实现的是std::cmp::PartialEq特征(类似其他语言的接口),但是并没有实现std::cmp::Eq特征,但是后者在其它数值类型上都有定义,说了这么多,可能大家还是云里雾里,用一个例子来举例:
Rust 的 HashMap 数据结构,是一个 KV 类型的 Hash Map 实现,它对于 K 没有特定类型的限制,但是要求能用作 K 的类型必须实现了 std::cmp::Eq 特征,因此这意味着你无法使用浮点数作为 HashMap 的 Key,来存储键值对,但是作为对比,Rust 的整数类型、字符串类型、布尔类型都实现了该特征,因此可以作为 HashMap 的 Key。
为了避免上面说的两个陷阱,你需要遵守以下准则:
避免在浮点数上测试相等性
当结果在数学上可能存在未定义时,需要格外的小心
来看个小例子:
fn main() {
// 断言0.1 + 0.2与0.3相等
assert!(0.1 + 0.2 == 0.3);
}你可能以为,这段代码没啥问题吧,实际上它会 panic(程序崩溃,抛出异常),因为二进制精度问题,导致了 0.1 + 0.2 并不严格等于 0.3,它们可能在小数点 N 位后存在误差。
那如果非要进行比较呢?可以考虑用这种方式 (0.1_f64 + 0.2 - 0.3).abs() < 0.00001 ,具体小于多少,取决于你对精度的需求。
讲到这里,相信大家基本已经明白了,为什么操作浮点数时要格外的小心,但是还不够,下面再来一段代码,直接震撼你的灵魂:
fn main() {
let abc: (f32, f32, f32) = (0.1, 0.2, 0.3);
let xyz: (f64, f64, f64) = (0.1, 0.2, 0.3);
println!("abc (f32)");
println!(" 0.1 + 0.2: {:x}", (abc.0 + abc.1).to_bits());
println!(" 0.3: {:x}", (abc.2).to_bits());
println!();
println!("xyz (f64)");
println!(" 0.1 + 0.2: {:x}", (xyz.0 + xyz.1).to_bits());
println!(" 0.3: {:x}", (xyz.2).to_bits());
println!();
assert!(abc.0 + abc.1 == abc.2);
assert!(xyz.0 + xyz.1 == xyz.2);
}运行该程序,输出如下:
abc (f32)
0.1 + 0.2: 3e99999a
0.3: 3e99999a
xyz (f64)
0.1 + 0.2: 3fd3333333333334
0.3: 3fd3333333333333
thread 'main' panicked at 'assertion failed: xyz.0 + xyz.1 == xyz.2',
➥ch2-add-floats.rs.rs:14:5
note: run with `RUST_BACKTRACE=1` environment variable to display
➥a backtrace
仔细看,对 f32 类型做加法时,0.1 + 0.2 的结果是 3e99999a,0.3 也是 3e99999a,因此 f32 下的 0.1 + 0.2 == 0.3 通过测试,但是到了 f64 类型时,结果就不一样了,因为 f64 精度高很多,因此在小数点非常后面发生了一点微小的变化,0.1 + 0.2 以 4 结尾,但是 0.3 以3结尾,这个细微区别导致 f64 下的测试失败了,并且抛出了异常。
NaN
对于数学上未定义的结果,例如对负数取平方根 -42.1.sqrt() ,会产生一个特殊的结果:Rust 的浮点数类型使用 NaN (not a number) 来处理这些情况。
所有跟 NaN 交互的操作,都会返回一个 NaN,而且 NaN 不能用来比较,下面的代码会崩溃:
fn main() {
let x = (-42.0_f32).sqrt();
assert_eq!(x, x);
}出于防御性编程的考虑,可以使用 is_nan() 等方法,可以用来判断一个数值是否是 NaN :
fn main() {
let x = (-42.0_f32).sqrt();
if x.is_nan() {
println!("未定义的数学行为")
}
}数字运算
Rust 支持所有数字类型的基本数学运算:加法、减法、乘法、除法和取模运算。下面代码各使用一条 let 语句来说明相应运算的用法:
fn main() {
// 加法
let sum = 5 + 10;
// 减法
let difference = 95.5 - 4.3;
// 乘法
let product = 4 * 30;
// 除法
let quotient = 56.7 / 32.2;
// 求余
let remainder = 43 % 5;
}这些语句中的每个表达式都使用了数学运算符,并且计算结果为一个值,然后绑定到一个变量上。附录 B 中给出了 Rust 提供的所有运算符的列表。
再来看一个综合性的示例:
fn main() {
// 编译器会进行自动推导,给予twenty i32的类型
let twenty = 20;
// 类型标注
let twenty_one: i32 = 21;
// 通过类型后缀的方式进行类型标注:22是i32类型
let twenty_two = 22i32;
// 只有同样类型,才能运算
let addition = twenty + twenty_one + twenty_two;
println!("{} + {} + {} = {}", twenty, twenty_one, twenty_two, addition);
// 对于较长的数字,可以用_进行分割,提升可读性
let one_million: i64 = 1_000_000;
println!("{}", one_million.pow(2));
// 定义一个f32数组,其中42.0会自动被推导为f32类型
let forty_twos = [
42.0,
42f32,
42.0_f32,
];
// 打印数组中第一个值,并控制小数位为2位
println!("{:.2}", forty_twos[0]);
}位运算
Rust 的位运算基本上和其他语言一样
fn main() {
// 无符号8位整数,二进制为00000010
let a: u8 = 2; // 也可以写 let a: u8 = 0b_0000_0010;
// 二进制为00000011
let b: u8 = 3;
// {:08b}:左高右低输出二进制01,不足8位则高位补0
println!("a value is {:08b}", a);
println!("b value is {:08b}", b);
println!("(a & b) value is {:08b}", a & b);
println!("(a | b) value is {:08b}", a | b);
println!("(a ^ b) value is {:08b}", a ^ b);
println!("(!b) value is {:08b}", !b);
println!("(a << b) value is {:08b}", a << b);
println!("(a >> b) value is {:08b}", a >> b);
let mut a = a;
// 注意这些计算符除了!之外都可以加上=进行赋值 (因为!=要用来判断不等于)
a <<= b;
println!("(a << b) value is {:08b}", a);
}对于移位运算,Rust 会检查它是否超出该整型的位数范围,如果超出,则会报错 overflow。比如,一个 8 位的整型,如果试图移位 8 位,就会报错,但如果移位 7 位就不会。Rust 这样做的理由也很简单,如果移位太多,那么这个移位后的数字就是全 0 或者全 1,所以移位操作不如直接写 0 或者 -1,这很可能意味着这里的代码是有问题的。需要注意的是,不论 debug 模式还是 release 模式,Rust 都会检查溢出。
fn main() {
let a: u8 = 255;
let b = a>>7; // ok
let b = a<<7; // ok
let b = a>>8; // overflow
let b = a<<8; // overflow
}序列(Range)
Rust 提供了一个非常简洁的方式,用来生成连续的数值,例如 1..5,生成从 1 到 4 的连续数字,不包含 5 ;1..=5,生成从 1 到 5 的连续数字,包含 5,它的用途很简单,常常用于循环中:
for i in 1..=5 {
println!("{}",i);
}
最终程序输出:
1
2
3
4
5
序列只允许用于数字或字符类型,原因是:它们可以连续,同时编译器在编译期可以检查该序列是否为空,字符和数字值是 Rust 中仅有的可以用于判断是否为空的类型。如下是一个使用字符类型序列的例子:
for i in 'a'..='z' {
println!("{}",i);
}
使用 As 完成类型转换
Rust 中可以使用 As 来完成一个类型到另一个类型的转换,其最常用于将原始类型转换为其他原始类型,但是它也可以完成诸如将指针转换为地址、地址转换为指针以及将指针转换为其他指针等功能。你可以在这里了解更多相关的知识。
有理数和复数
Rust 的标准库相比其它语言,准入门槛较高,因此有理数和复数并未包含在标准库中:
有理数和复数
任意大小的整数和任意精度的浮点数
固定精度的十进制小数,常用于货币相关的场景
好在社区已经开发出高质量的 Rust 数值库:num。
按照以下步骤来引入 num 库:
创建新工程
cargo new complex-num && cd complex-num在
Cargo.toml中的[dependencies]下添加一行num = "0.4.0"将
src/main.rs文件中的main函数替换为下面的代码运行
cargo run
use num::complex::Complex;
fn main() {
let a = Complex { re: 2.1, im: -1.2 };
let b = Complex::new(11.1, 22.2);
let result = a + b;
println!("{} + {}i", result.re, result.im)
}字符、布尔、单元类型
字符类型(char)
下面的代码展示了几个颇具异域风情的字符:
fn main() {
let c = 'z';
let z = 'ℤ';
let g = '国';
let heart_eyed_cat = '😻';
}在 Rust 语言中这些都是字符,Rust 的字符不仅仅是 ASCII,所有的 Unicode 值都可以作为 Rust 字符,包括单个的中文、日文、韩文、emoji 表情符号等等,都是合法的字符类型。Unicode 值的范围从 U+0000 ~ U+D7FF 和 U+E000 ~ U+10FFFF。不过“字符”并不是 Unicode 中的一个概念,所以人在直觉上对“字符”的理解和 Rust 的字符概念并不一致。
由于 Unicode 都是 4 个字节编码,因此字符类型也是占用 4 个字节:
fn main() {
let x = '中';
println!("字符'中'占用了{}字节的内存大小", size_of_val(&x));
}输出如下:
$ cargo run
Compiling ...
字符'中'占用了4字节的内存大小
注意,Rust 的字符只能用
''来表示,""是留给字符串的。
布尔(bool)
Rust 中的布尔类型有两个可能的值:true 和 false,布尔值占用内存的大小为 1 个字节:
fn main() {
let t = true;
let f: bool = false; // 使用类型标注,显式指定f的类型
if f {
println!("这是段毫无意义的代码");
}
}使用布尔类型的场景主要在于流程控制,例如上述代码的中的 if 就是其中之一。
单元类型(unit)
单元类型就是 () ,唯一的值也是 () 。
只能说,再不起眼的东西,都有其用途,在目前为止的学习过程中,大家已经看到过很多次 fn main() 函数的使用吧?那么这个函数返回什么呢?
没错, main 函数就返回这个单元类型 (),你不能说 main 函数无返回值,因为没有返回值的函数在 Rust 中是有单独的定义的:发散函数( diverging functions ),顾名思义,无法收敛的函数。
例如常见的 println!() 的返回值也是单元类型 ()。
再比如,你可以用 () 作为 map 的值,表示我们不关注具体的值,只关注 key。 这种用法和 Go 语言的 struct{} 类似,可以作为一个值用来占位,但是完全不占用任何内存。
语句和表达式
Rust 的函数体是由一系列语句组成,最后由一个表达式来返回值,例如:
fn add_with_extra(x: i32, y: i32) -> i32 {
let x = x + 1; // 语句
let y = y + 5; // 语句
x + y // 表达式
}
语句会执行一些操作但是不会返回一个值,而表达式会在求值后返回一个值,因此在上述函数体的三行代码中,前两行是语句,最后一行是表达式。
对于 Rust 语言而言,这种基于语句(statement)和表达式(expression)的方式是非常重要的。基于表达式是函数式语言的重要特征,表达式总要返回值。
语句
let a = 8;
let b: Vec<f64> = Vec::new();
let (a, c) = ("hi", false);
以上都是语句,它们完成了一个具体的操作,但是并没有返回值,因此是语句。
由于 let 是语句,因此不能将 let 语句赋值给其它值,如下形式是错误的:
let b = (let a = 8);
错误如下:
error: expected expression, found statement (`let`) // 期望表达式,却发现`let`语句
--> src/main.rs:2:13
|
2 | let b = let a = 8;
| ^^^^^^^^^
|
= note: variable declaration using `let` is a statement `let`是一条语句
error[E0658]: `let` expressions in this position are experimental
// 下面的 `let` 用法目前是试验性的,在稳定版中尚不能使用
--> src/main.rs:2:13
|
2 | let b = let a = 8;
| ^^^^^^^^^
|
= note: see issue #53667 <https://github.com/rust-lang/rust/issues/53667> for more information
= help: you can write `matches!(<expr>, <pattern>)` instead of `let <pattern> = <expr>`
以上的错误告诉我们 let 是语句,不是表达式,因此它不返回值,也就不能给其它变量赋值。但是该错误还透漏了一个重要的信息, let 作为表达式已经是试验功能了,也许不久的将来,我们在 stable rust 下可以这样使用。
表达式
表达式会进行求值,然后返回一个值。例如 5 + 6,在求值后,返回值 11,因此它就是一条表达式。
表达式可以成为语句的一部分,例如 let y = 6 中,6 就是一个表达式,它在求值后返回一个值 6(有些反直觉,但是确实是表达式)。
调用一个函数是表达式,因为会返回一个值,调用宏也是表达式,用花括号包裹最终返回一个值的语句块也是表达式,总之,能返回值,它就是表达式:
fn main() {
let y = {
let x = 3;
x + 1
};
println!("The value of y is: {}", y);
}上面使用一个语句块表达式将值赋给 y 变量,语句块长这样:
{
let x = 3;
x + 1
}
该语句块是表达式的原因是:它的最后一行是表达式,返回了 x + 1 的值,注意 x + 1 不能以分号结尾,否则就会从表达式变成语句, 表达式不能包含分号。这一点非常重要,一旦你在表达式后加上分号,它就会变成一条语句,再也不会返回一个值,请牢记!
最后,表达式如果不返回任何值,会隐式地返回一个 () 。
fn main() {
assert_eq!(ret_unit_type(), ())
}
fn ret_unit_type() {
let x = 1;
// if 语句块也是一个表达式,因此可以用于赋值,也可以直接返回
// 类似三元运算符,在Rust里我们可以这样写
let y = if x % 2 == 1 {
"odd"
} else {
"even"
};
// 或者写成一行
let z = if x % 2 == 1 { "odd" } else { "even" };
}函数
Rust 的函数跟其他语言几乎没有什么区别。
在函数界,有一个函数只闻其名不闻其声,可以止小孩啼!在程序界只有 hello,world! 可以与之媲美,它就是 add 函数:
fn add(i: i32, j: i32) -> i32 {
i + j
}
该函数如此简单,但是又是如此的五脏俱全,声明函数的关键字 fn,函数名 add(),参数 i 和 j,参数类型和返回值类型都是 i32:
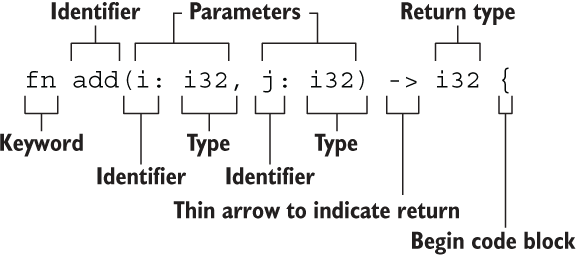
函数要点
函数名和变量名使用蛇形命名法(snake case),例如
fn add_two() {}函数的位置可以随便放,Rust 不关心我们在哪里定义了函数,只要有定义即可
每个函数参数都需要标注类型
函数参数
Rust 是静态类型语言,因此需要你为每一个函数参数都标识出它的具体类型,例如:
fn main() {
another_function(5, 6.1);
}
fn another_function(x: i32, y: f32) {
println!("The value of x is: {}", x);
println!("The value of y is: {}", y);
}another_function 函数有两个参数,其中 x 是 i32 类型,y 是 f32 类型,然后在该函数内部,打印出这两个值。这里去掉 x 或者 y 的任何一个的类型,都会报错:
fn main() {
another_function(5, 6.1);
}
fn another_function(x: i32, y) {
println!("The value of x is: {}", x);
println!("The value of y is: {}", y);
}错误如下:
error: expected one of `:`, `@`, or `|`, found `)`
--> src/main.rs:5:30
|
5 | fn another_function(x: i32, y) {
| ^ expected one of `:`, `@`, or `|` // 期待以下符号之一 `:`, `@`, or `|`
|
= note: anonymous parameters are removed in the 2018 edition (see RFC 1685)
// 匿名参数在 Rust 2018 edition 中就已经移除
help: if this is a parameter name, give it a type // 如果y是一个参数名,请给予它一个类型
|
5 | fn another_function(x: i32, y: TypeName) {
| ~~~~~~~~~~~
help: if this is a type, explicitly ignore the parameter name // 如果y是一个类型,请使用_忽略参数名
|
5 | fn another_function(x: i32, _: y) {
| ~~~~
函数返回
在上一章节语句和表达式中有提到,在 Rust 中函数就是表达式,因此可以把函数的返回值直接赋给调用者。
函数的返回值就是函数体最后一条表达式的返回值,当然也可以使用 return 提前返回,下面的函数使用最后一条表达式来返回一个值:
fn plus_five(x:i32) -> i32 {
x + 5
}
fn main() {
let x = plus_five(5);
println!("The value of x is: {}", x);
}x + 5 是一条表达式,求值后,返回一个值,因为它是函数的最后一行,因此该表达式的值也是函数的返回值。
再来看两个重点:
let x = plus_five(5),说明用一个函数的返回值来初始化x变量,因此侧面说明了在 Rust 中函数也是表达式,这种写法等同于let x = 5 + 5;x + 5没有分号,因为它是一条表达式,这个在上一节中也有详细介绍
再来看一段代码,同时使用 return 和表达式作为返回值:
fn plus_or_minus(x:i32) -> i32 {
if x > 5 {
return x - 5
}
x + 5
}
fn main() {
let x = plus_or_minus(5);
println!("The value of x is: {}", x);
}plus_or_minus 函数根据传入 x 的大小来决定是做加法还是减法,若 x > 5 则通过 return 提前返回 x - 5 的值,否则返回 x + 5 的值。
Rust 中的特殊返回类型
无返回值()
例如单元类型 (),是一个零长度的元组。它没啥作用,但是可以用来表达一个函数没有返回值:
函数没有返回值,那么返回一个
()通过
;结尾的语句返回一个()
例如下面的 report 函数会隐式返回一个 ():
use std::fmt::Debug;
fn report<T: Debug>(item: T) {
println!("{:?}", item);
}
与上面的函数返回值相同,但是下面的函数显式的返回了 ():
fn clear(text: &mut String) -> () {
*text = String::from("");
}
在实际编程中,你会经常在错误提示中看到该 () 的身影出没,假如你的函数需要返回一个 u32 值,但是如果你不幸的以 表达式; 的语句形式作为函数的最后一行代码,就会报错:
fn add(x:u32,y:u32) -> u32 {
x + y;
}
错误如下:
error[E0308]: mismatched types // 类型不匹配
--> src/main.rs:6:24
|
6 | fn add(x:u32,y:u32) -> u32 {
| --- ^^^ expected `u32`, found `()` // 期望返回u32,却返回()
| |
| implicitly returns `()` as its body has no tail or `return` expression
7 | x + y;
| - help: consider removing this semicolon
还记得我们在语句与表达式中讲过的吗?只有表达式能返回值,而 ; 结尾的是语句,在 Rust 中,一定要严格区分表达式和语句的区别,这个在其它语言中往往是被忽视的点。
永不返回的发散函数 !
当用 ! 作函数返回类型的时候,表示该函数永不返回( diverging functions ),特别的,这种语法往往用做会导致程序崩溃的函数:
fn dead_end() -> ! {
panic!("你已经到了穷途末路,崩溃吧!");
}
下面的函数创建了一个无限循环,该循环永不跳出,因此函数也永不返回:
fn forever() -> ! {
loop {
//...
};
}